前回の記事で静的なWEBサイトに対するスクレイピングのやり方について書いたが、「静的」があるということは当然ながら「動的」もある。 今回は動的なWEBサイトに対してスクレイピングを行う方法についてまとめた。
- 静的なページと同じ感覚でスクレイピングすると…
- 動的なページでスクレイピングを行うには
- 環境とディレクトリ構成
- Seleniumとブラウザドライバのインストール
- Seleniumで画面を操作する
- 要素の取得と出力
- おわりに
静的なページと同じ感覚でスクレイピングすると…
この記事では、以前Vuexを使う例で色々作ったサンプルページを試しに解析してみることにする。 ページ内の機能の詳細については下記の記事をご覧いただきたい。
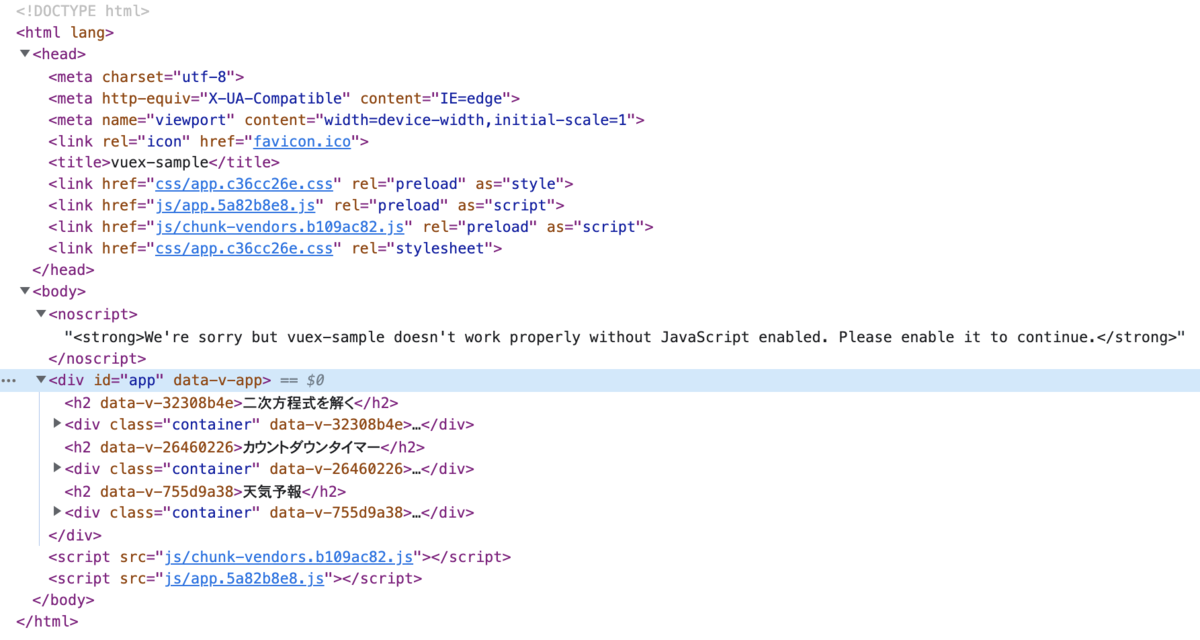
ページのHTMLを確認すると下のようになっている。
<div id="app"></div>の中身がアプリケーションの本体になるので、この中から必要なものを取得すればよさそうだ。
静的なページに対してスクレイピングした時と同じ手順に則り、まず始めにurlopenでHTMLファイルをダウンロードする。
import shutil from urllib import request with request.urlopen('https://momoshiro407.github.io/vuexSample/') as response, open('sample.html', 'wb') as f: shutil.copyfileobj(response, f)
しかしそのHTMLファイルの中を見てみると…
<!DOCTYPE html> <html lang=""> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width,initial-scale=1"> <link rel="icon" href="favicon.ico"> <title>vuex-sample</title> <link href="css/app.c36cc26e.css" rel="preload" as="style"> <link href="js/app.5a82b8e8.js" rel="preload" as="script"> <link href="js/chunk-vendors.b109ac82.js" rel="preload" as="script"> <link href="css/app.c36cc26e.css" rel="stylesheet"> </head> <body><noscript><strong>We're sorry but vuex-sample doesn't work properly without JavaScript enabled. Please enable it to continue.</strong></noscript> <div id="app"></div> <script src="js/chunk-vendors.b109ac82.js"></script> <script src="js/app.5a82b8e8.js"></script> </body> </html>
肝心の<div id="app"></div>の中身が空になっていて取得できていない!
Vueで作られたページは、アクセスしてからJavascriptによって<div id="app"></div>の中身が生成され画面がレンダリングされるので、単にurlopenを使うだけだとレンダリング前の状態を取ってしまうことになる。
このような動的なページをスクレイピングする方法を次項から記述していく。
動的なページでスクレイピングを行うには
動的なページのスクレイピングにはいくつか方法があるが、今回はSeleniumというフレームワークを利用する。
Selenium(の中のWebDriver API)はブラウザ操作の自動化を可能にするフレームワークであり、本来はブラウザの自動テストなどを行うためにあるもののようだが、これを利用すれば動的なWEBページに対するスクレイピングも可能になる。
Seleniumによって画面を自動操作し、自分が欲しい状態の画面が表示されたタイミングで要素の解析・取得を行うという流れだ。
Seleniumを使用する時には、自動化するブラウザ毎に別途ドライバをインストールする必要がある。
この記事ではChromeでページを開いてスクレイピングしていくことにする。
環境とディレクトリ構成
環境
- Python 3.9.0
- beautifulsoup4 4.11.1
- Selenium 4.1.5
ディレクトリ構成
. ├── csv │ └── weather_info.csv ├── dynamic_analysis.py └── dynamic_analysis_bs.py
Seleniumとブラウザドライバのインストール
はじめにSeleniumをインストールする。
$ pip install selenium
次に、Seleniumでブラウザを動かすために必要なドライバだが、今回はChromeを使うのでChromeDriverをインストールする。
ChromeDriver公式ページから自分でダウンロード&インストールしてもいいが、下記のpipコマンドでchromedriver-binaryをインストールすればパスを通さずに利用できるのでこちらの方が簡単である。(後述のchromedriver_binaryのインポートが必要)
ただし、利用中のChromeと同じバージョンのドライバをインストールしないとSeleniumで使えないので、コマンドの場合はバージョンを指定する必要がある。(下はバージョン101.0.4951.41の例)
$ pip install chromedriver-binary==101.0.4951.41
もしくは、webdriver-managerというライブラリをインストールする方法もある。
これを利用すればプログラムの実行時に自動でバージョンの更新を行ってくれるようになるので、使用ブラウザのバージョンが上がっても一々手動で更新せずに済む。(後述のwebdriver_managerのインポートが必要)
$ pip install webdriver-manager
Seleniumとブラウザドライバがインストールできればこれで準備完了だ。
Seleniumで画面を操作する
スクレイピングの前に、Seleniumで画面を操作する基本的な例をいくつかみてみる。
ページ下部の「天気予報」エリアを操作して任意の場所の天気情報を表示してみよう。
画面を表示する
まずはブラウザを開き対象のページを表示して数秒後にブラウザを閉じる例を見てみる。
chromedriver_binaryまたはwebdriver_managerを使用する場合で若干異なるので両方について記述する。
chromedriver_binaryを利用する場合
import time import chromedriver_binary from selenium import webdriver driver = webdriver.Chrome() driver.get('https://momoshiro407.github.io/vuexSample/') time.sleep(3) driver.quit()
はじめにchromedriver_binaryとwebdriverモジュールをインポートし、webdriver.Chrome()でWebDriverオブジェクトを生成する。
そしてWebDriver.get()の引数に表示したいページのURLの文字列を渡せば、これだけでもうSeleniumでChromeを起動し対象のページを表示することができる。
time.sleep()で3秒待機した後quit()でブラウザを閉じる。
webdriver_managerを利用する場合
import time from webdriver_manager.chrome import ChromeDriverManager from selenium import webdriver driver = webdriver.Chrome(ChromeDriverManager().install()) driver.get('https://momoshiro407.github.io/vuexSample/') time.sleep(3) driver.quit()
はじめにChromeDriverManagerとwebdriverモジュールをインポートする。
ChromeDriverManagerオブジェクトのinstall()は最新版のドライバをインストールし、さらにインストール先のパスを返却するのでこれを引数にしてWebDriverオブジェクトを生成する。
これ以降はwebdriver_managerを使う方式で記載していく。
headlessで実行する場合
ブラウザを表示せずにプログラムを実行(headlessで実行)することもできる。
はじめにOptionsオブジェクトを生成し'--headless'のオプションを追加する。
このOptionsオブジェクトを、WebDriverオブジェクト生成時のキーワード引数optionsに設定するとheadlessで実行することができる。
from selenium.webdriver.chrome.options import Options options = Options() options.add_argument('--headless') # chromedriver_binaryを利用する場合 driver = webdriver.Chrome(options=options) # webdriver_managerを利用する場合 driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
画面要素の取得
初期のページが表示できたので次はページ内の要素を取得していこう。
なお、ページの表示直後だとレンダリングが完了しておらず要素が取得できなかったり、取得処理自体に時間がかかったりする場合があるので、適宜sleep()で一定時間の待機を挟んだほうがいい。
find_element()は1つの要素(WebElementオブジェクト)、find_elements()は複数の要素(WebElementのリスト)を取得する。
第1引数には要素の取得方法をByクラスで指定し、第2引数にはその抽出条件を指定する。
Byで指定可能な取得方法は下記のものがある。
By.ID:id属性の値を用いて要素を指定する
By.NAME:name属性の値を用いて要素を指定する
By.TAG_NAME:タグ名を用いて要素を指定する
By.CLASS_NAME:クラス名を用いて要素を指定する
By.LINK_TEXT:a要素の文字列を用いて要素を指定する
By.PARTIAL_LINK_TEXT:a要素の部分文字列を用いて要素を指定する
By.CSS_SELECTOR:CSSセレクタを用いて要素を指定する
By.XPATH:XPathを用いて要素を指定する
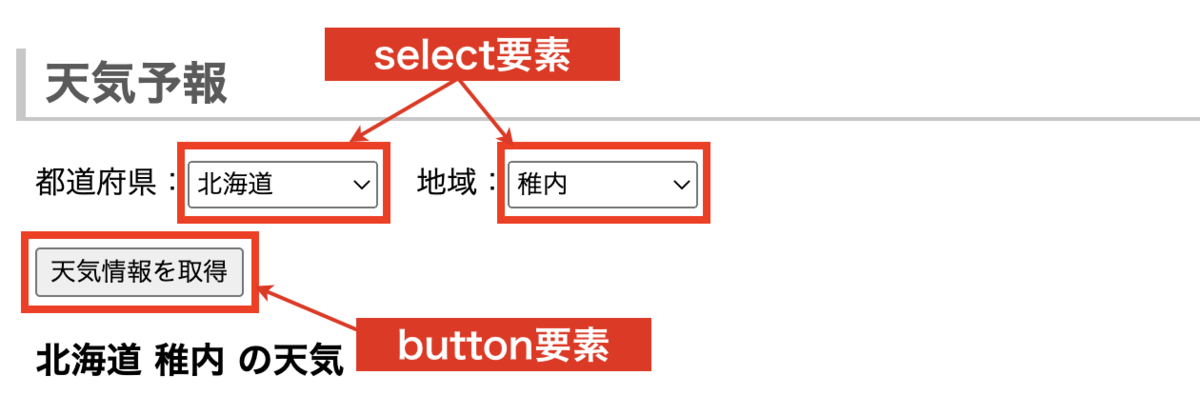
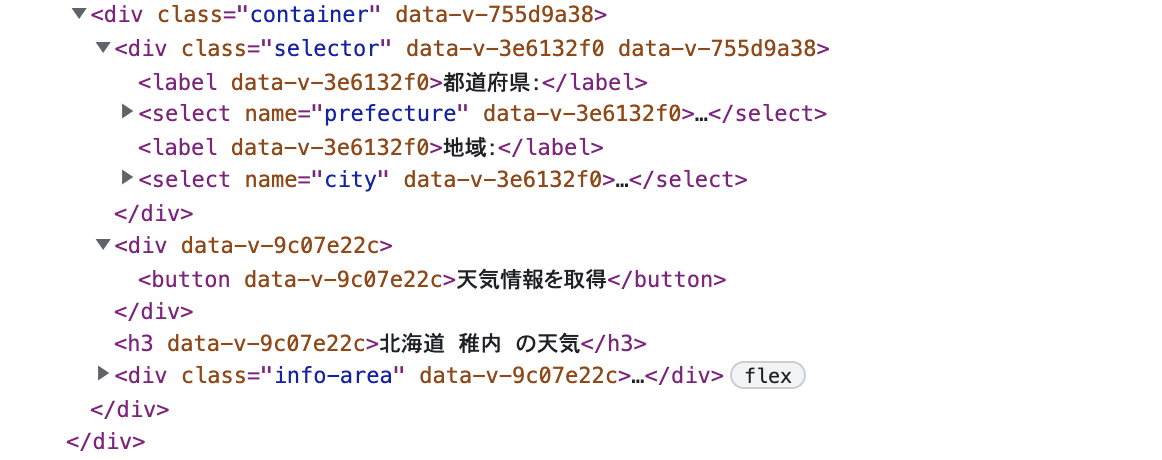
これを使って下記のselect要素やbutton要素を取得してみる。
from selenium.webdriver.common.by import By //省略 time.sleep(3) # 都道府県プルダウン、地域プルダウンのselect要素を取得 pref_pulldown = driver.find_element(By.NAME, 'prefecture') city_pulldown = driver.find_element(By.NAME, 'city') # 天気情報取得ボタンの要素を取得してクリック calc_button = driver.find_elements(By.CSS_SELECTOR, 'div.container')[2].find_element(By.TAG_NAME, 'button') calc_button.click() time.sleep(3) driver.quit()
都道府県プルダウン、地域プルダウンのselect要素はそれぞれprefecture、cityというname属性を持っているのでBy.NAMEで取得できる。
天気情報取得ボタンについては、まずdiv.container(この要素は画面内に3つあるが、その中で天気情報は3番目になる)をBy.CSS_SELECTORで取り、その内部のbutton要素を直接By.TAG_NAMEで取得すればいい。
さらに、取得した要素に対してclick()関数を用いるとその要素をクリックすることができる。
プルダウンを操作する
取得したselect要素を操作して天気情報を表示する地域を選択したいのだが、これらの要素をただクリックするだけでは特定の値の選択状態にすることができない。
これを行うためにはSeleniumのSelectオブジェクトを利用する必要があるので、まずはSelectクラスをインポートしておこう。
from selenium.webdriver.common.by import By from selenium.webdriver.support.select import Select //省略 # 天気情報を取得する操作 # 都道府県プルダウン、地域プルダウンの要素を取得 pref_pulldown = driver.find_element(By.NAME, 'prefecture') city_pulldown = driver.find_element(By.NAME, 'city') # Selectオブジェクトを生成 pref_select = Select(pref_pulldown) city_select = Select(city_pulldown) # Selectオブジェクトを選択状態にする pref_select.select_by_value('11') # optionのvalueで指定(11:埼玉県) city_select.select_by_index(1) # optionのインデックス値で指定(1:熊谷) # 天気情報取得ボタンの要素を取得してクリック calc_button = driver.find_elements(By.CSS_SELECTOR, 'div.container')[2].find_element(By.TAG_NAME, 'button') calc_button.click() time.sleep(3) driver.quit()
取得したselect要素を引数としてpref_select、city_selectというSelectオブジェクトをそれぞれ生成する。
Selectオブジェクトはselect_by_value()またはselect_by_index()関数で選択状態にすることができる。
select_by_value()は選択肢のvalueを指定し、select_by_index()は選択肢のインデックスを指定する。
例えば、select_by_value()を使って都道府県プルダウンの「埼玉県」を選択したければ11、select_by_index()を使って地域プルダウンの「熊谷」を選択したければ1を渡せばいい。

このようにselect要素を操作したのち天気情報取得ボタンの要素をクリックすれば天気情報が表示される。
要素の取得と出力
ブラウザを操作して天気情報を画面に表示したので、その内部の色々な情報を取得してCSVファイルに出力してみる。
3日分の天気予報が表示されるので、日付、最高気温、最低気温、降水確率を日毎に抽出して出力してみよう。
Seleniumだけで出力まで行う場合とBeautifulSoupを併用する場合の2パターン記述する。


① Seleniumのみ
これまでと同じようにHTMLの構造を確認しながらfind_element()やfind_elements()を駆使して必要な要素を取得していく。
import re, time, csv from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.select import Select // 省略 time.sleep(3) # 天気情報の要素を取得して表示、出力 weather_infomations = driver.find_elements(By.CLASS_NAME, 'info-container') results = [] for info in weather_infomations: row = [] row.append(info.find_element(By.CSS_SELECTOR, 'p > span:first-child').text) # 日付 max_temperature_value = re.search( r'[+-]?\d+', info.find_element(By.CSS_SELECTOR, 'ul > li.max-temperature').text) # 最高気温 min_temperature_value = re.search( r'[+-]?\d+', info.find_element(By.CSS_SELECTOR, 'ul > li.min-temperature').text) # 最低気温 max_temperature = max_temperature_value.group() if max_temperature_value is not None else '' min_temperature = min_temperature_value.group() if min_temperature_value is not None else '' row.append(max_temperature) row.append(min_temperature) # 降水確率 rainy_percent_list = info.find_element(By.CSS_SELECTOR, 'table > tr:nth-child(2)') \ .find_elements(By.CSS_SELECTOR, 'td:not(:first-child)') for item in rainy_percent_list: percent_value = re.search(r'\d+', item.text) percent = percent_value.group() if percent_value is not None else '' row.append(percent) results.append(row) driver.quit() # CSVファイル出力 with open('csv/weather_info.csv', 'w') as f: writer = csv.writer(f) writer.writerows(results)
各日の天気情報はinfo-containerというclass属性を持つdivだが、info-containerはここでしか使われていないのでBy.CLASS_NAMEで簡単に取得できる。
それらを取得した結果をループで取り出しさらに中身を分析していく。
.textで最高気温、最低気温、降水確率の要素の文字列を取得すると「20℃」や「50%」のように単位まで付いてきてしまう。数字だけ取り出したいので正規表現操作モジュールreのsearch()を利用し、気温は(-になることもあるので)-?\d+、降水確率は\d+を指定して整数に合致する部分だけ抽出する。
これら必要なものを取得して結果をまとめるresultsに全て突っ込んでしまえばもうブラウザを表示しておく必要はないのでquit()で閉じる。
最後に書き込み用のCSVファイルを開き、writerオブジェクトのwriterows()を使ってresultsをファイルに書き込んで行けば完了だ。
6月22日(水),26,21,60,40,30,50 6月23日(木),30,22,40,40,40,40 6月24日(金),33,23,30,30,30,30
② SeleniumとBeautifulSoupの併用
Seleniumでは表示中のHTMLをdriver.page_sourceとして取得できるので、これを利用してBeautifulSoupオブジェクトを生成し解析を行うことができる。
Seleniumで全て行うよりもBeautifulSoupを使う方が高速なので、「画面操作→表示の変更→スクレイピング」の流れが1回で済むのであればこちらの方がよさそうだ。
BeautifulSoupオブジェクトを生成すればもうブラウザを開いておく必要はないので、早々にブラウザを閉じることができる。
これ以降やることは①と全く同じで、find_element()やfind_elements()を使っていた部分をBeautifulSoupオブジェクトの関数に置き換えただけである。
import re, time, csv from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.select import Select from bs4 import BeautifulSoup // 省略 time.sleep(3) # BeautifulSoupオブジェクトを生成 element = BeautifulSoup(driver.page_source, 'html.parser') # page_sourceの取得が完了したのでここでブラウザを閉じる driver.quit() info_area = element.select_one('.info-area') # 天気情報の要素を取得して表示、出力 weather_infomations = element.select('.info-container') results = [] for info in weather_infomations: row = [] row.append(info.select_one('p > span:first-child').text) # 日付 max_temperature_value = re.search( r'[+-]?\d+', info.select_one('ul > li.max-temperature').text) # 最高気温 min_temperature_value = re.search( r'[+-]?\d+', info.select_one('ul > li.min-temperature').text) # 最低気温 max_temperature = max_temperature_value.group() if max_temperature_value is not None else '' min_temperature = min_temperature_value.group() if min_temperature_value is not None else '' row.append(max_temperature) row.append(min_temperature) # 降水確率 rainy_percent_list = info.select_one('table > tr:nth-child(2)').select('td:not(:first-child)') for item in rainy_percent_list: percent_value = re.search(r'\d+', item.text) percent = percent_value.group() if percent_value is not None else '' row.append(percent) results.append(row) # CSVファイル出力 with open('csv/weather_info.csv', 'w') as f: writer = csv.writer(f) writer.writerows(results)
なお、今回はpage_sourceの取得からBeautifulSoupオブジェクトの生成・解析まで一連のプログラムで行なっているが、page_sourceを一旦HTMLファイルとして保存してからそのファイルに対してスクレイピングを行うことも可能だ。
# page_sourceを一旦HTMLファイルとして出力 with open('XXXX.html', 'w', encoding='utf-8') as f: f.write(driver.page_source)
おわりに
動的なページのスクレイピングについて一通りまとめた。
なお、Seleniumを使ったスクレイピングは静的なページでももちろん可能だがいささか仰々しい感じがするので、その場合はurllib.requestを使う方がいいだろう。
まずurllib.requestで試してみてうまくいかない場合はSeleniumを発動する、程度の考えで使い分ければいいと思う。
画面上で色々な操作が必要なものやログインが必要なものなど様々なWEBページが存在するが、いかに複雑なページが相手でもこれで自由に欲しい情報を取ってくることが可能(なはず)だ!
参考
Selenium クイックリファレンス