人は皆ネット上に転がっている様々なデータを利用して何か分析したり作ったりしたいと思う時があるだろう、たぶん。
そういう時に、データベースを公開しているサービスがデータ提供のAPIを用意してくれていればそれを利用すればいいのだが、必ずしもそうなっているとは限らない。
APIがない場合は自分でスクレイピングをしてデータを取ってくる必要がある。
そういう感じで私自身何度かスクレイピングの技術に触れてくる機会があったので、せっかくだから静的なWEBページを対象にしたスクレイピングの基本についてまとめておくことにした。
なお、スクレイピングが明確に禁止されているページでは当然ながら使ってはならないし、スクレイピングが認められている(禁止はされていない)ページであっても必要以上に負荷をかけるようなことは避けたほうがいい。
静的なページとは?
まず最初に静的なページと動的なページの違いについてざっくり述べておくと下記のような感じになる。
静的なページ
- サーバ上にある既に成形されたHTMLを取得して表示するだけ
- アクセスする人、タイミングなどによって表示内容が変わらない
動的なページ
- アクセスした時点でJavascriptによってHTMLの内容が作られレンダリングされる
- アクセスする人、タイミングなどによって表示内容が変わることがある
今回は静的なページのスクレイピングの例として、このブログのトップページ(この記事を投稿する前の状態)に対して色々やってみることにする。
環境とディレクトリ構成
環境
- Python 3.9.0
- beautifulsoup4 4.11.1
ディレクトリ構成
. ├── csv │ └── output.csv ├── html │ └── sample.html ├── static_download.py └── static_analysis.py
スクレイピング対象のHTMLの取得はstatic_download.py、HTMLの解析はstatic_analysis.pyで行う。
スクレイピング対象のHTMLを取得する
スクレイピングを行うためにはあらかじめ対象ページのHTMLデータを取得する必要があるので、まずurllib.requestモジュールでHTMLデータを取得する方法を述べる。
なお、HTMLデータの取得とBeautiful Soupによる解析を一連の処理で行うこともできるが、ここでは一旦HTMLデータをファイルに保存しその HTMLファイルに対して解析を行う手順にしている。
スクレイピングが問題ないページであっても、コード作成中に試行錯誤して何度もアクセスすると余計な負荷をかけてしまう可能性があるので、このように一旦ローカルのファイルを介してやるといい。
import os import shutil from urllib import request from urllib.error import HTTPError, URLError # ファイルの保存先のディレクトリ save_dir = os.path.dirname(os.path.abspath(__file__)) + '/html/' # 保存ファイル save_file = save_dir + 'sample.html' # スクレイピング対象のページのURL download_url = 'https://mmsrtech.com/' # htmlファイルを取得 try: with request.urlopen(download_url) as response, open(save_file, 'wb') as f: shutil.copyfileobj(response, f) except HTTPError as e: print('Error Code: ', e.code) except URLError as e: print('Error Reason: ', e.reason)
urllib.requestモジュールのurlopen関数は、取得対象ページのURL指定によってリクエストを作成し、対象ページのHTML情報をレスポンスとして返す。レスポンスはファイルライクオブジェクトでありFileオブジェクトと同じように扱える。
念のためurlopenで起きる可能性のある例外HTTPError、URLErrorを捕捉する処理を入れておくと良い。
URLErrorはネットワーク接続がない場合や指定のサーバがない場合に送出される例外で、reason属性(文字列またはBaseExceptionオブジェクト)を持っているのでエラーの理由を表示することができる。
HTTPErrorはurlopen()がリクエストを処理できない場合(URLが不正、アクセス権限がないなど)に送出される例外で、こちらもreason属性を持っている他、code属性なども持っている。
なお、HTTPErrorはURLErrorのサブクラスなので、URLErrorよりも先にHTTPErrorを捕捉する必要がある。
さらに、保存先のファイルをバイナリの書き込みモードwbで開きレスポンスを書き込む。
with句は1つにまとめることができるので、request.urlopen(download_url) as responseの後ろにカンマ区切りでopen(save_file, 'wb') as fを繋げられる。
Python標準モジュールshutilのcopyfileobj()関数で、レスポンスを任意のファイルに保存(コピー)できる。
HTMLの解析と要素の取得
BeautifulSoupオブジェクトの生成
では保存したHTMLファイルから必要な要素を抽出していこう。
HTMLの解析と要素の抽出に使用するのはBeautiful Soup 4である。
はじめにBeautiful Soup 4のモジュールbs4をインストールする。
$ pip install bs4
HTMLファイルを読み込んでBeautifulSoupオブジェクトを生成する部分までを示す。
import os from bs4 import BeautifulSoup # htmlファイルの格納先のディレクトリ html_dir = os.path.dirname(os.path.abspath(__file__)) + '/html/' # htmlファイル html_file = html_dir + 'sample.html' with open(html_file, 'r') as fr: # BeautifulSoupオブジェクトを生成 element = BeautifulSoup(fr, 'html.parser') # 以下、要素を取得していく
はじめにbs4モジュールからBeautifulSoupクラスをインポートする。
with文を用いてHTMLファイルを開き、第1引数にFileオブジェクト、第2引数にパーサーを指定してBeautifulSoupオブジェクトを生成する。
今回の解析対象はHTMLファイルなのでパーサーはhtml.parser(Pythonの標準モジュール)を指定する。
なお、パーサーを明示しないと下記の警告が出るのだが、その場合でもBeautifulSoupがパーサーを自動判断してくれるので一応動く。
GuessedAtParserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("html.parser"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
ちなみに、HTMLをファイルに保存しない場合は、request.urlopen()をここで使用しレスポンスを直接渡してBeautifulSoupオブジェクトを生成すればいい。
with request.urlopen('https://mmsrtech.com/') as response: # BeautifulSoupオブジェクトを生成 element = BeautifulSoup(response, 'html.parser')
HTMLの要素の取得
要素の取得方法はいくつかあるので基本的なものについて記述する。
タグ名を指定
手始めにブログのタイトルを取得してみる。
ブラウザでスクレイピング対象のページを表示し、開発者ツールを開いてブログタイトルの要素を確認する。
headタグ内のtitleを取れば良さそうだ。

with open(save_file, 'r') as f: element = BeautifulSoup(f, 'html.parser') print(element.title) print(element.title.text)
<title>HAKUTAI Tech Notes</title> HAKUTAI Tech Notes
最も簡単な方法は欲しい要素のタグ名を直接.で指定することである。
該当する要素が複数あれば最初の一個だけ取得される。
element.title.textのようにすれば要素の内容(innerText)を取得できる。
find()とfind_all()
id、classなどのCSS属性を指定して要素を取得する方法の一つに、BeautifulSoupオブジェクトのfind()関数やfind_all()関数を利用するものがある。
ここでは各記事の見出しのa要素を取得してみる。
class属性がentry-title-linkのものを抽出すればよさそうだ。
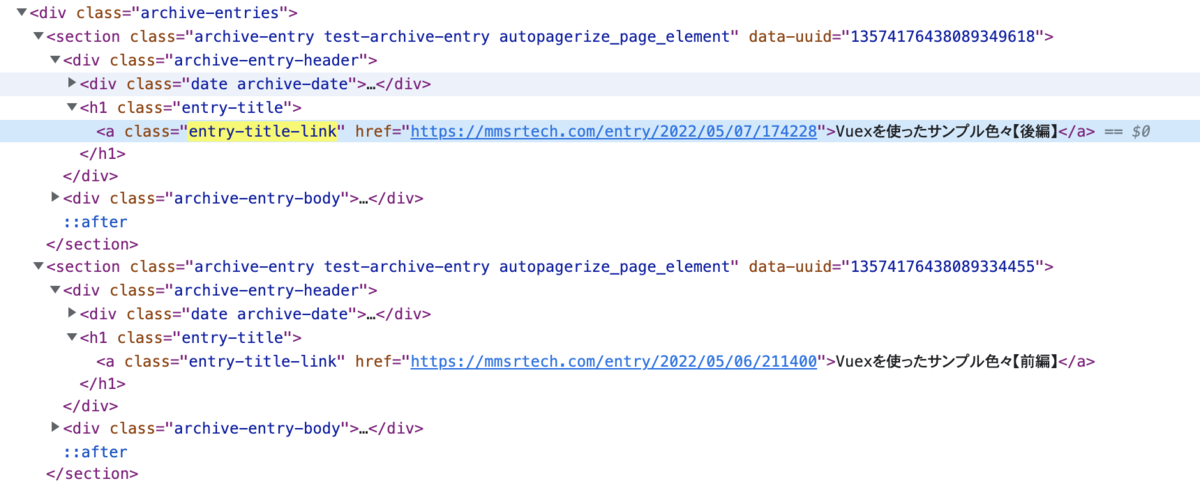
条件に合致する要素のうち先頭の一件だけ取得できる。
HTMLの中に取得対象が1件しかないと分かっている場合は、後述のfind_all()よりもこちらを使った方がいい。
find()は第1引数にタグ名を指定(省略可能)し、各種CSS属性はキーワード引数として指定する。
id属性の指定はid=でいいのだが、class属性の指定はclass=ではなくclass_=になることに注意。
classはPythonの予約語なのでそのままキーワード引数にすると構文エラーになってしまうからである。
なお、取得結果はBeautifulSoupのタグオブジェクトbs4.element.Tagというものになる。
with open(save_file, 'r') as f: element = BeautifulSoup(f, 'html.parser') find_entry_title = element.find('a', class_="entry-title-link") print(find_entry_title)
<a class="entry-title-link" href="https://mmsrtech.com/entry/2022/05/07/174228">Vuexを使ったサンプル色々【後編】</a>
条件に合致する要素を全て取得できる。
引数の指定はfind()と変わらないが、こちらはキーワード引数のlimitを指定して取得件数を絞ることができる。
取得結果はbs4.element.ResultSetオブジェクトというTagオブジェクトのリストになっている。
with open(save_file, 'r') as f: element = BeautifulSoup(f, 'html.parser') print('\n------ find_all() ------') find_entry_titles = element.find_all('a', class_="entry-title-link") [print(title) for title in find_entry_titles] print('\n------ find_all() limitによる件数指定 ------') find_entry_titles = element.find_all('a', class_="entry-title-link", limit=3) [print(title) for title in find_entry_titles]
------ find_all() ------ <a class="entry-title-link" href="https://mmsrtech.com/entry/2022/05/07/174228">Vuexを使ったサンプル色々【後編】</a> <a class="entry-title-link" href="https://mmsrtech.com/entry/2022/05/06/211400">Vuexを使ったサンプル色々【前編】</a> <a class="entry-title-link" href="https://mmsrtech.com/entry/2022/01/10/213921">【Vue.js / Typescript】画像一覧+ページネーションを実装する(フロント側のみ)</a> <a class="entry-title-link" href="https://mmsrtech.com/entry/2021/12/29/130449">ProcessingとPythonで雪を降らせる</a> <a class="entry-title-link" href="https://mmsrtech.com/entry/2021/12/11/174946"> Typescriptで中身が複雑なオブジェクトの型を定義する</a> <a class="entry-title-link" href="https://mmsrtech.com/entry/2021/07/03/220324">AngularとPaper.jsで簡易なデジタイザを作る5</a> <a class="entry-title-link" href="https://mmsrtech.com/entry/2021/06/26/180740">AngularとPaper.jsで簡易なデジタイザを作る4</a> ------ find_all() limitによる件数指定 ------ <a class="entry-title-link" href="https://mmsrtech.com/entry/2022/05/07/174228">Vuexを使ったサンプル色々【後編】</a> <a class="entry-title-link" href="https://mmsrtech.com/entry/2022/05/06/211400">Vuexを使ったサンプル色々【前編】</a> <a class="entry-title-link" href="https://mmsrtech.com/entry/2022/01/10/213921">【Vue.js / Typescript】画像一覧+ページネーションを実装する(フロント側のみ)</a>
find_all()のキーワード引数には文字列だけでなく関数を与えることも可能なので、これを利用すればCSS属性の前方一致、後方一致、部分一致を考慮した取得もできる。
例として、class属性の前方にprofile-を含む要素、後方に-buttonを含む要素、-entries-を含む要素の取得はそれぞれ下記のようになる。
with open(save_file, 'r') as f: element = BeautifulSoup(f, 'html.parser') print('\n------ find_all() 前方一致 ------') find_elements = element.find_all(class_=lambda str: str and str.startswith("profile-")) [print(element.prettify()) for element in find_elements] print('\n------ find_all() 後方一致 ------') find_elements = element.find_all(class_=lambda str: str and str.endswith("-button")) [print(element.prettify()) for element in find_elements] print('\n------ find_all() 部分一致 ------') find_elements = element.find_all('li', class_=lambda str: str and "-entries-" in str) [print(element.prettify()) for element in find_elements]
キーワード引数class_に、各絞り込みを行うためのlambda関数を渡している。
lambda関数の内部で行なっている検索処理はごく一般的なもので、文字列strに対して前方一致ならstartswith()、後方一致ならendswith()、部分一致ならin演算子を用いて絞り込みを行なっている。
結果を出力する際に一部prettify()関数を使用している。
prettify()はHTMLを出力する時に改行やインデントを行なって整形してくれる関数で、階層が深いHTMLを表示する時などに使うと見やすくなる。
------ find_all() 前方一致 ------ <a class="profile-icon-link" href="https://mmsrtech.com/about"> <img alt="id:rozured" class="profile-icon" src="https://cdn.profile-image.st-hatena.com/users/rozured/profile.png?1640762446"/> </a> <img alt="id:rozured" class="profile-icon" src="https://cdn.profile-image.st-hatena.com/users/rozured/profile.png?1640762446"/> <div class="profile-about"> <a href="https://mmsrtech.com/about"> このブログについて </a> </div> ------ find_all() 後方一致 ------ <a class="hatena-follow-button js-hatena-follow-button" href="#"> <span class="subscribing"> <span class="foreground"> 読者です </span> <span class="background"> 読者をやめる </span> </span> <span class="unsubscribing" data-track-name="profile-widget-subscribe-button" data-track-once=""> <span class="foreground"> 読者になる </span> <span class="background"> 読者になる </span> </span> </a> <input class="search-module-button" type="submit" value="検索"> </input> <button class="btn quote-stock-close-message-button"> 閉じる </button> <button class="btn quote-stock-close-message-button"> 閉じる </button> <button class="btn quote-stock-close-message-button"> 閉じる </button> <a class="hatena-follow-button js-hatena-follow-button" href="#"> <span class="subscribing"> <span class="foreground"> 読者です </span> <span class="background"> 読者をやめる </span> </span> <span class="unsubscribing" data-track-name="profile-widget-subscribe-button" data-track-once=""> <span class="foreground"> 読者になる </span> <span class="background"> 読者になる </span> </span> </a> ------ find_all() 部分一致 ------ <li class="urllist-item recent-entries-item"> <div class="urllist-item-inner recent-entries-item-inner"> <a class="urllist-title-link recent-entries-title-link urllist-title recent-entries-title" href="https://mmsrtech.com/entry/2022/05/07/174228"> Vuexを使ったサンプル色々【後編】 </a> </div> </li> <li class="urllist-item recent-entries-item"> <div class="urllist-item-inner recent-entries-item-inner"> <a class="urllist-title-link recent-entries-title-link urllist-title recent-entries-title" href="https://mmsrtech.com/entry/2022/05/06/211400"> Vuexを使ったサンプル色々【前編】 </a> </div> </li> <li class="urllist-item recent-entries-item"> <div class="urllist-item-inner recent-entries-item-inner"> <a class="urllist-title-link recent-entries-title-link urllist-title recent-entries-title" href="https://mmsrtech.com/entry/2022/01/10/213921"> 【Vue.js / Typescript】画像一覧+ページネーションを実装する(フロント側のみ) </a> </div> </li> <li class="urllist-item recent-entries-item"> <div class="urllist-item-inner recent-entries-item-inner"> <a class="urllist-title-link recent-entries-title-link urllist-title recent-entries-title" href="https://mmsrtech.com/entry/2021/12/29/130449"> ProcessingとPythonで雪を降らせる </a> </div> </li> <li class="urllist-item recent-entries-item"> <div class="urllist-item-inner recent-entries-item-inner"> <a class="urllist-title-link recent-entries-title-link urllist-title recent-entries-title" href="https://mmsrtech.com/entry/2021/12/11/174946"> Typescriptで中身が複雑なオブジェクトの型を定義する </a> </div> </li>
select_one()とselect()
CSS属性を指定して要素を取得する関数にはfind()やfind_all()以外にもselect_one()やselect()がある。
取得できるものは両者とも同じなのだが、絞り込み条件の指定方法が異なる。
以下、実行結果はfind系と同じなので省略する。
条件に合致する要素を一件だけ取得できるもので、挙動はfind()と同じである。
select_one()の場合、絞り込み条件にはCSSセレクタの文字列をそのまま渡すことができる。
例えば、class属性がentry-title-linkのa要素であればa.entry-title-linkを指定すればいい。
with open(save_file, 'r') as f: element = BeautifulSoup(f, 'html.parser') # select_one() select_entry_title = element.select_one("a.entry-title-link") print(select_entry_title)
条件に合致する要素を全て取得できるもので、挙動はfind_all()と同じである。
こちらもキーワード引数のlimitを指定して取得件数を絞ることができる。
with open(save_file, 'r') as f: element = BeautifulSoup(f, 'html.parser') # select() select_entry_titles = element.select("a.entry-title-link") [print(title) for title in select_entry_titles] # select() limitによる件数指定 select_entry_titles = element.select("a.entry-title-link", limit=3) [print(title) for title in select_entry_titles]
select()でもCSS属性の前方一致、後方一致、部分一致を考慮した取得ができる。
find_all()の時と同じようにclass属性の前方にprofile-を含む要素、後方に-buttonを含む要素、-entries-を含む要素を取得してみよう。
with open(save_file, 'r') as f: element = BeautifulSoup(f, 'html.parser') # select() 前方一致 select_elements = element.select("[class^='profile-']") [print(element.prettify()) for element in select_elements] # select() 後方一致 select_elements = element.select("[class$='-button']") [print(element.prettify()) for element in select_elements] # select() 部分一致 select_elements = element.select("li[class*='-entries-']") [print(element.prettify()) for element in select_elements]
CSSセレクタでは前方一致要素名[属性^="XXXX"]、後方一致要素名[属性$="XXXX"]、部分一致要素名[属性*="XXXX"]の指定ができるのでそれをそのままselect()の引数に渡すだけでいい。
キーワード引数にlambda関数を渡す必要があったfind_all()と比べてずいぶんシンプルに書けると思う。
find()系もselect()系も基本的に取得可能な要素は同じなのでどちらを使うかは好みの問題だと思うが、個人的にはより直感的にCSSセレクタを渡すだけで済むselect()系のほうがいいかな。(慣れているので)
要素取得後の処理の例
単純に要素を取得するだけでなく、それらに対して色々な処理を行う例をいくつか示す。
指定期間に含まれる記事の情報を抽出
2022年に投稿された記事のみを抽出してその投稿日、タイトル、URLを表示してみる。
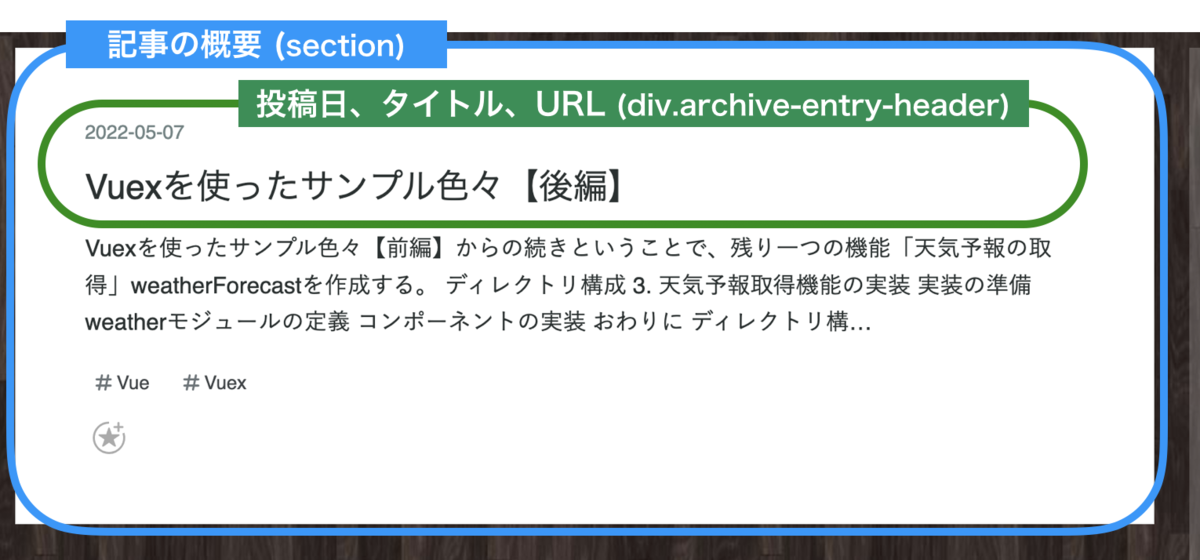
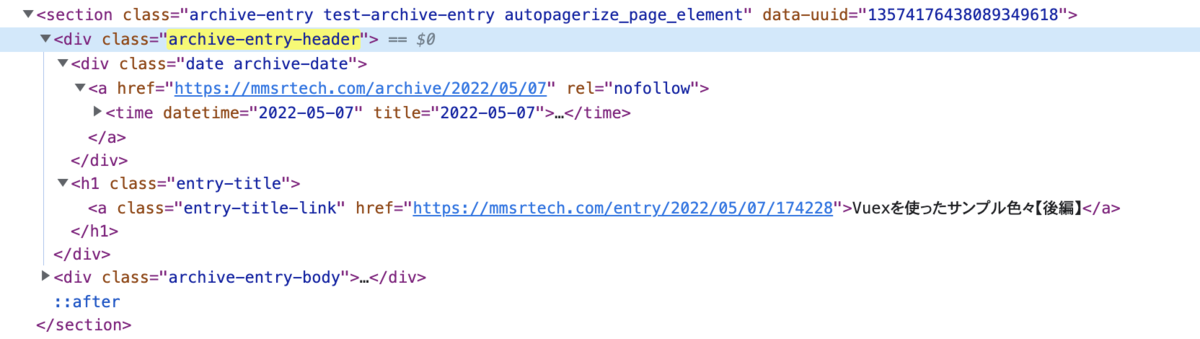
トップページに表示されている記事の概要はそれぞれsection要素として並んでおり、各section内のdiv.archive-entry-headerに必要な情報が一通り含まれているのでまずこれらを取得する。
取得したdiv内部のtime要素にdatetime属性があるので、この値を基に指定年月日でフィルタリングする。
import os from bs4 import BeautifulSoup from datetime import datetime // 省略 with open(save_file, 'r') as f: element = BeautifulSoup(f, 'html.parser') articles = element.select('div.archive-entry-header') filtered_articles = [] for article in articles: # 抽出した投稿日の文字列をdatetimeオブジェクトに変換 posted_datetime = datetime.strptime(article.time['datetime'], '%Y-%m-%d') # 取得対象期間に含まれる記事の要素のみ抽出 if datetime(2022, 1, 1) <= posted_datetime < datetime(2023, 1, 1): entry_title = article.select_one('a.entry-title-link') filtered_articles.append([ article.time['datetime'], entry_title.text, entry_title['href'], ]) [print(item) for item in filtered_articles]
['2022-05-07', 'Vuexを使ったサンプル色々【後編】', 'https://mmsrtech.com/entry/2022/05/07/174228'] ['2022-05-06', 'Vuexを使ったサンプル色々【前編】', 'https://mmsrtech.com/entry/2022/05/06/211400'] ['2022-01-10', '【Vue.js / Typescript】画像一覧+ページネーションを実装する(フロント側のみ)', 'https://mmsrtech.com/entry/2022/01/10/213921']
まず、select() で対象となるdivを取得してarticlesという変数に格納する。
articlesはResultSetオブジェクトなので、forで要素を1個ずつ取り出してarticleとして使っていく。
articleの内部にあるtime要素はarticle.timeで参照でき、さらにそのdatetime属性の値はブラケット表記でarticle.time['datetime']とすれば取得できる。
datetime属性の値が取れてしまえば後はそれをdatetimeオブジェクトに変換し、比較演算子を使って2022年1月1日〜2022年12月31日に含まれる場合だけ出力用のリストに必要なものを突っ込んでいけばいい。
記事のタグの抽出
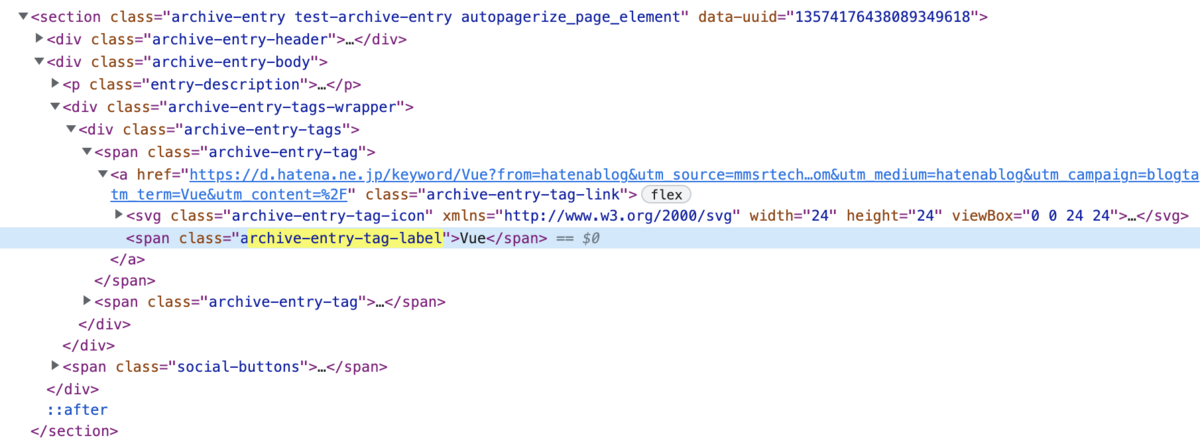
各記事の概要にはタグが付いているのでそれらの文字列を抽出し全て表示する。
タグの文字列が入っているspan要素はclass属性archive-entry-tag-labelを持っているのでそれを直接指定すればいい。
ただし、記事によっては同じタグが付いているものもあり単純に抽出しただけは重複していることもあるので、一意の状態にしてから表示する。

with open(save_file, 'r') as f: element = BeautifulSoup(f, 'html.parser') tag_elements = element.select('.archive-entry-tag-label') # setオブジェクト(順不同、重複なし)に変換 tag_set = {tag.text for tag in tag_elements} # アルファベット順(大文字・小文字の区別無し)に並べたリストに変換 tag_list = sorted(list(tag_set), key=str.lower) print(tag_list)
['Angular', 'pagination', 'Processing', 'Python', 'TypeScript', 'Vue', 'Vue.js', 'Vuex']
まず、select()で対象のspanを取得してtag_elementsという変数に格納する。
このtag_elementsの各要素のtextを取り出してリストを作るのだが、内容を一意にしたいので集合内包表記を利用して一旦集合(setオブジェクト)tag_setを生成する。
後はtag_setをリストに変換するだけだが内容が順不同に入っているので、key=str.lowerを引数に指定したsorted()で要素をアルファベット順に並べかえる。
スクレイピング結果の出力
大抵はスクレイピングした結果をファイル出力して何か別の作業に使うことになるだろう。
ここでは例として、前項で作成したfiltered_articles(2022年の記事の投稿日、タイトル、URLのリスト)の内容をCSVファイルに出力してみる。
import os import csv from bs4 import BeautifulSoup from datetime import datetime // 省略 # csvファイルの保存先のディレクトリ csv_dir = os.path.dirname(os.path.abspath(__file__)) + '/csv/' # csvファイル csv_file = csv_dir + 'output.csv' with open(html_file, 'r') as fr, open(csv_file, 'w') as fw: element = BeautifulSoup(fr, 'html.parser') // 省略 # filtered_articlesのcsvファイル出力 writer = csv.writer(fw) writer.writerows(filtered_articles)
まずcsvモジュールをインポートする。
書き込み用のCSVファイルを開き、そのFileオブジェクトをcsvモジュールのwriter()に渡してwriterオブジェクトを生成する。
writerオブジェクトにはCSVファイルへの書き込みをサポートする様々な関数が用意されている。
ここで使うのはwriterows()で、引数に出力対象のリストを渡すだけで各要素を1行ずつCSVファイルに書き込んでくれる。
2022-05-07,Vuexを使ったサンプル色々【後編】,https://mmsrtech.com/entry/2022/05/07/174228 2022-05-06,Vuexを使ったサンプル色々【前編】,https://mmsrtech.com/entry/2022/05/06/211400 2022-01-10,【Vue.js / Typescript】画像一覧+ページネーションを実装する(フロント側のみ),https://mmsrtech.com/entry/2022/01/10/213921
おわりに
スクレイピング対象のHTMLのダウンロードからスクレイピング結果の出力まで一通り追ってみた。
基本的に、ページのHTMLを眺めてみて取得したい要素の特定さえ出来てしまえば後は何とでもなる。
なお、今回わざわざ「静的なページ」と銘打ったということは、、、?もちろん「動的なページ」のスクレイピングについても触れる予定です。
動的なページに対するスクレイピングは今回の方法では上手くいかないので、次の記事ではそれについて述べることにする。
参考